


作业优先级与抢占
前置条件
部署volcano
修改configmap
kubectl edit cm -n volcano-system volcano-scheduler-configmapapiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill, reclaim, preempt" # 添加reclaim(队列资源回收), preempt(任务抢占)
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: capacity # 添加capacity(队列资源)
- name: predicates
- name: nodeorder
- name: binpack测试脚本
namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test-volcanopriority.yaml
# 低优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 1
---
# 高优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 10
queue.yaml
# 队列 限制资源为12个GPU
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: test-queue
namespace: test-volcano
spec:
reclaimable: false
capability:
nvidia.com/gpu: 12
jobs_low_priority.yaml
# 三个低优先级的job: job-1、job-2、job-3, 分别占2、3、4个GPU
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-1
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: low-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 2
ports:
- containerPort: 80
restartPolicy: OnFailure
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-2
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: low-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 3
ports:
- containerPort: 80
restartPolicy: OnFailure
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-3
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: low-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 4
ports:
- containerPort: 80
restartPolicy: OnFailurejobs_high_priority.yaml
# 四个高优先级的job: job-a、job-b、job-c, 每个占3个GPU
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-a
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: high-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 3
ports:
- containerPort: 80
command: ["/bin/sh", "-c"]
args: ["echo 'job2-1开始'; sleep 20; echo 'job2-1完成'"]
restartPolicy: Never
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-b
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: high-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 3
ports:
- containerPort: 80
command: ["/bin/sh", "-c"]
args: ["echo 'job2-2开始'; sleep 30; echo 'job2-2完成'"]
restartPolicy: Never
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-c
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: high-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 3
ports:
- containerPort: 80
command: ["/bin/sh", "-c"]
args: ["echo 'job2-3开始'; sleep 40; echo 'job2-3完成'"]
restartPolicy: Never
---
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-d
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: high-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: nginx-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
resources:
limits:
nvidia.com/gpu: 3
ports:
- containerPort: 80
restartPolicy: OnFailure
运行测试
launch.sh
kubectl delete -f ./queue.yaml
kubectl delete -f ./priority.yaml
kubectl delete -f ./namespace.yaml
kubectl apply -f ./namespace.yaml
kubectl apply -f ./priority.yaml
kubectl apply -f ./queue.yaml
kubectl apply -f ./jobs_low_priority.yaml
sleep 20
kubectl apply -f ./jobs_high_priority.yaml
结果
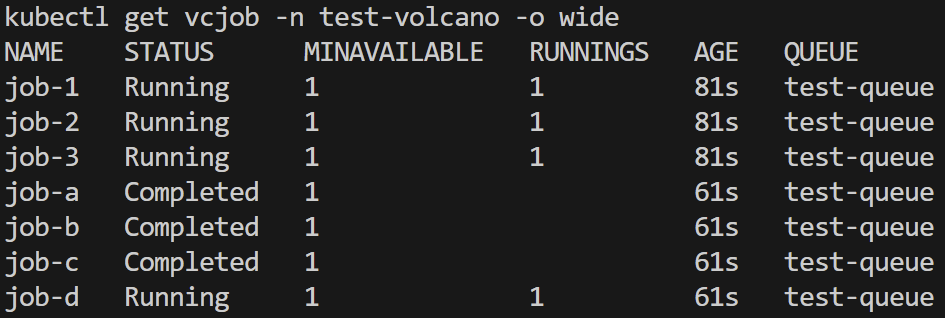
低优先级作业启动并运行

高优先级作业启动,队列资源不足,低优先级作业被抢占挂起
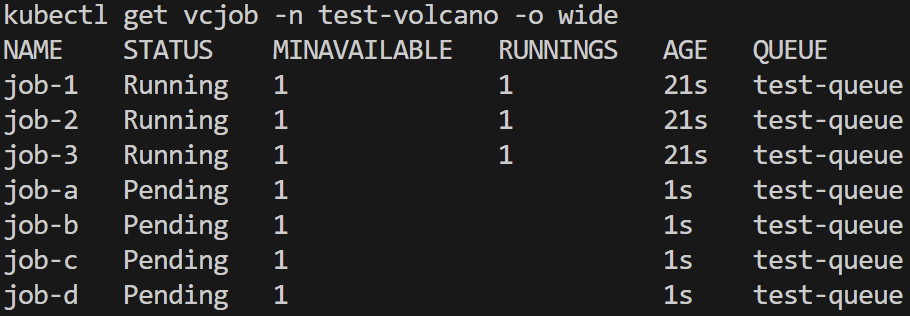
低优先级作业pod退出,新pod等待
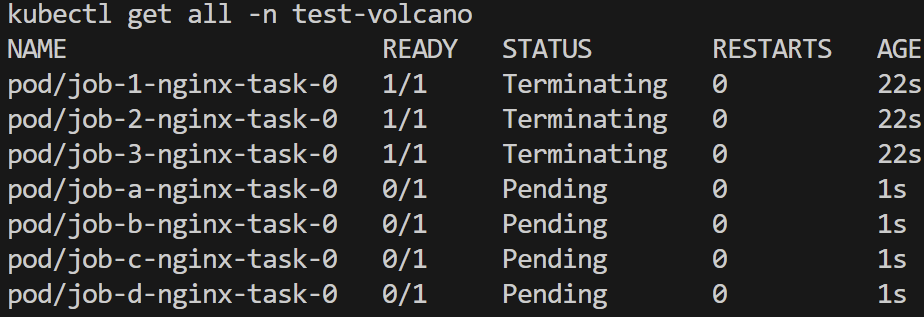
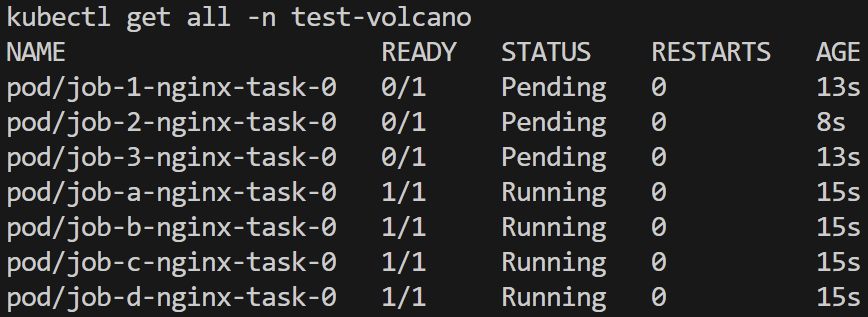
高优先级作业成功运行
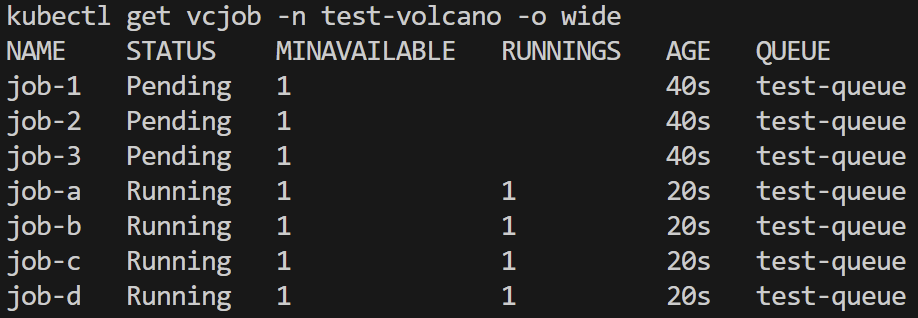
高优先级作业先后完成,低优先级作业再次启动
vGPU
前置条件
配置volcano虚拟GPU组件
修改configmap
kubectl edit cm -n volcano-system volcano-scheduler-configmapapiVersion: v1
data:
volcano-scheduler.conf: |
actions: "enqueue, allocate, backfill, reclaim, preempt"
tiers:
- plugins:
- name: priority
- name: gang
enablePreemptable: false
- name: conformance
- plugins:
- name: overcommit
- name: drf
enablePreemptable: false
- name: deviceshare
arguments:
deviceshare.VGPUEnable: true # 添加 vgpu 插件
deviceshare.SchedulePolicy: binpack # 调度策略. binpack(打包) / spread(分摊)
- name: capacity
- name: predicates
- name: nodeorder
- name: binpack显存限制
通过设置volcano.sh/vgpu-memory限制显存
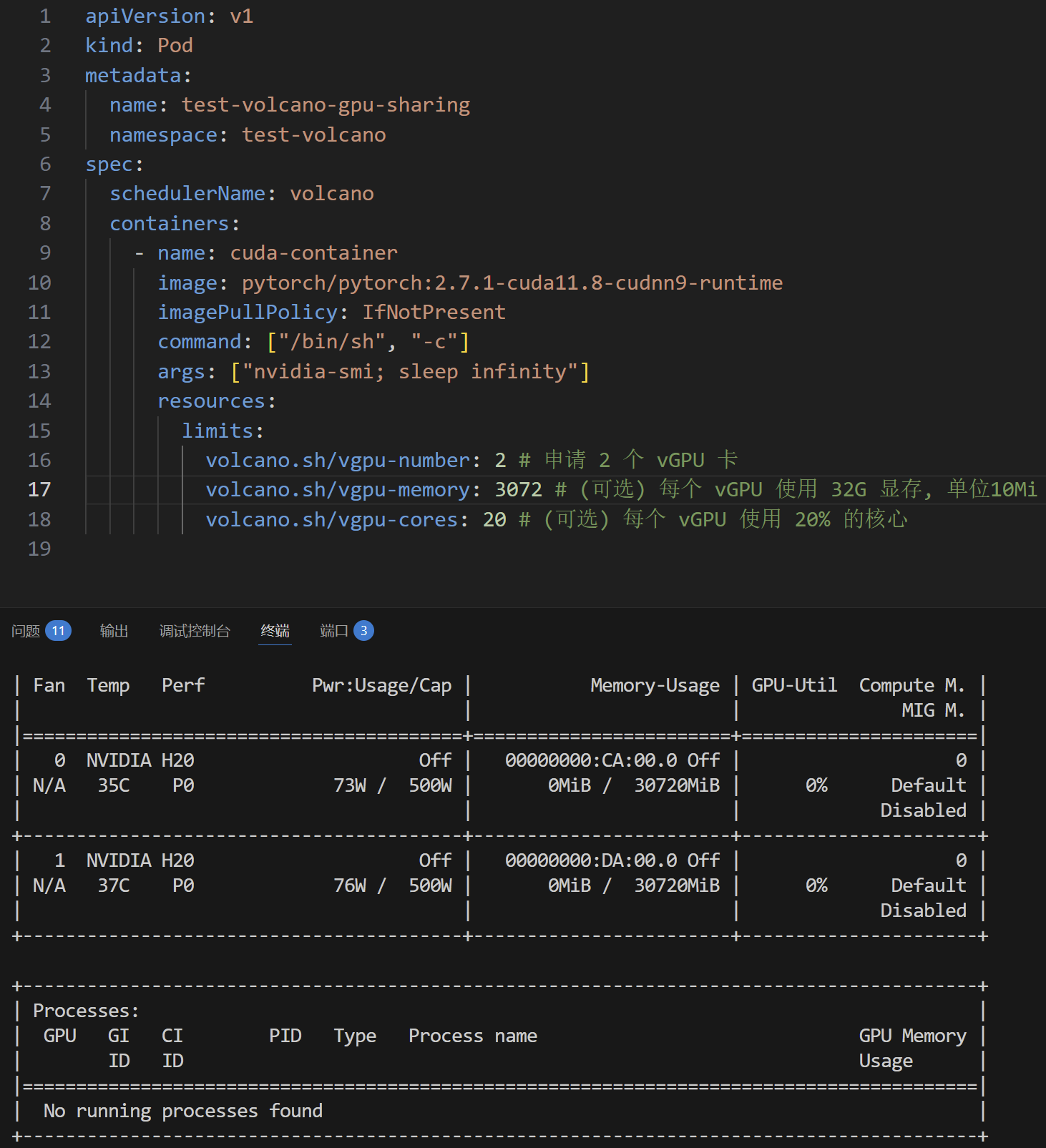
虚拟显存作业抢占
注:
v1.13之前有bug,需要按照https://github.com/volcano-sh/volcano/pull/4520修改代码并从源码构建volcano
v1.13中已解决
测试脚本
namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test-volcano
priority.yaml
# 低优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 1
---
# 高优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 10
queue.yaml
# 队列 限制资源为2个vGPU, 共50G虚拟显存
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: test-queue
namespace: test-volcano
spec:
reclaimable: false
capability:
volcano.sh/vgpu-number: 2
volcano.sh/vgpu-memory: 51200 # 50G
job_low_priority.yaml
# 低优先级job: job-1, 最高占40G显存
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-1
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: low-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: pytorch-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: pytorch
image: pytorch/pytorch:2.7.1-cuda11.8-cudnn9-runtime
imagePullPolicy: IfNotPresent
resources:
limits:
volcano.sh/vgpu-number: 1
volcano.sh/vgpu-memory: 40960 # 40G
command: ["/bin/sh", "-c"]
args: ["nvidia-smi; sleep infinity"]
restartPolicy: OnFailure
job_high_priority.yaml
# 高优先级job: job-a, 最高占20G显存
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: job-a
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: "test-queue"
priorityClassName: high-priority
policies:
- event: PodFailed
action: RestartJob
- event: TaskCompleted
action: CompleteJob
tasks:
- replicas: 1
name: pytorch-task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- name: pytorch
image: pytorch/pytorch:2.7.1-cuda11.8-cudnn9-runtime
imagePullPolicy: IfNotPresent
resources:
limits:
volcano.sh/vgpu-number: 1
volcano.sh/vgpu-memory: 20480 # 20G
command: ["/bin/sh", "-c"]
args: ["nvidia-smi; sleep 40"]
restartPolicy: Never
运行测试
launch.sh
kubectl delete -f ./queue.yaml
kubectl delete -f ./priority.yaml
kubectl delete -f ./namespace.yaml
kubectl apply -f ./namespace.yaml
kubectl apply -f ./priority.yaml
kubectl apply -f ./queue.yaml
kubectl apply -f ./job_low_priority.yaml
sleep 20
kubectl apply -f ./job_high_priority.yaml
结果
低优先级作业启动并运行

高优先级作业启动并运行,vgpu-memory资源不足,低优先级作业被抢占挂起

高优先级作业完成,低优先级作业再次运行

真实负载
测试脚本
namespace.yaml
apiVersion: v1
kind: Namespace
metadata:
name: test-volcano
priority.yaml
# 低优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 1
---
# 高优先级
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 10
queue.yaml
# 队列 限制资源为16个vGPU, 共128G虚拟显存
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: test-queue
namespace: test-volcano
spec:
reclaimable: false
capability:
volcano.sh/vgpu-number: 16
volcano.sh/vgpu-memory: 131072 # 128G
storage.yaml(已配置nfs)
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-sc-static
provisioner: kubernetes.io/no-provisioner
reclaimPolicy: Retain
volumeBindingMode: Immediate
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv-static
spec:
capacity:
storage: 256Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
storageClassName: nfs-sc-static
nfs:
path: /data/nvme3n1/fuyou/srv/nfs
server: 172.17.100.13
readOnly: false
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc-static
namespace: test-volcano
spec:
storageClassName: nfs-sc-static
accessModes:
- ReadWriteMany
resources:
requests:
storage: 256Gi
volumeName: nfs-pv-static
infer/llama2.yaml(例,已配置docker私有仓库,训练脚本来自Tally)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: llama-2-7b
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: dl-queue
priorityClassName: high-priority
policies:
- event: PodFailed
action: AbortJob
volumes:
- mountPath: /mnt
volumeClaimName: nfs-pvc-static
tasks:
- replicas: 1
name: task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
restartPolicy: OnFailure
containers:
- name: pt
image: 172.17.100.13:5123/test-workloads
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c"]
args:
- |
mkdir -p /mnt/output/llama2;
cd /mnt/tally/tally-bench;
HF_ENDPOINT=https://hf-mirror.com HF_HOME=./data \
python scripts/launch.py \
--framework pytorch \
--benchmark llama-2-7b \
--batch-size 1 \
--runtime 30 \
--infer > /mnt/output/llama2/infer.log 2>&1
resources:
limits:
volcano.sh/vgpu-number: 1
volcano.sh/vgpu-memory: 16384
train/bert.yaml(例)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: bert
namespace: test-volcano
spec:
minAvailable: 1
schedulerName: volcano
queue: dl-queue
priorityClassName: low-priority
policies:
- event: PodFailed
action: AbortJob
volumes:
- mountPath: /mnt
volumeClaimName: nfs-pvc-static
tasks:
- replicas: 1
name: task
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
restartPolicy: OnFailure
containers:
- name: pt
image: 172.17.100.13:5123/test-workloads
imagePullPolicy: IfNotPresent
command: ["/bin/sh", "-c"]
args:
- |
mkdir -p /mnt/output/bert;
cd /mnt/tally/tally-bench;
HF_ENDPOINT=https://hf-mirror.com HF_HOME=./data \
python scripts/launch.py \
--framework pytorch \
--benchmark bert \
--batch-size 64 \
--runtime 120 \
--train > /mnt/output/bert/train.log 2>&1
resources:
limits:
volcano.sh/vgpu-number: 1 # 申请 1 个 vGPU 卡
volcano.sh/vgpu-memory: 32768 # (可选) 每个 vGPU 使用 32G 设备显存, 单位Mi
运行测试
launch.sh
kubectl delete -f storage.yaml
kubectl delete -f queue.yaml
kubectl delete -f priority.yaml
kubectl delete -f namespace.yaml
kubectl apply -f namespace.yaml
kubectl apply -f priority.yaml
kubectl apply -f queue.yaml # 128G
kubectl apply -f storage.yaml
kubectl apply -f train/bert.yaml # 32G
sleep 5
kubectl apply -f train/gpt2.yaml # 32G
sleep 5
kubectl apply -f train/pegasus.yaml # 32G
sleep 5
kubectl apply -f train/pointnet.yaml # 16G
sleep 5
kubectl apply -f train/resnet50.yaml # 16G
sleep 5
kubectl apply -f infer/llama2.yaml # 16G
sleep 5
kubectl apply -f infer/stable-diffusion.yaml # 8G
sleep 5
kubectl apply -f infer/yolo6m.yaml # 32G
评论区