


强化学习的数学原理 笔记
基础
- 状态(State):s
- 动作(Action):a
- 策略(Policy):\pi(a|s),状态s下选择动作a的条件概率
- 奖励(Reward):r(s,a)
- 轨迹(Trajectories):\tau,状态-动作-奖励链,s_1\xrightarrow[r=0]{a_1}s_2\xrightarrow[r=1]{a_2}s_3
- 回报(returns):\tau 中奖励的和或折(discounted)和 \sum_r\gamma^i r_i\ ,\ \gamma\in(0,1)
- episodes:有限的轨迹
马尔可夫决策过程(MDPs)
定义
- 状态空间:\mathcal{S}
- 动作空间:\mathcal{A(s)}
- 奖励空间:\mathcal{R}(s,a)
系统模型
- 状态转移概率:p(s'|s,a),\ \forall (s,a)\ \sum_{s'\in\mathcal{S}}p(s'|s,a)=1
- 奖励概率:p(r|s,a),\ \forall(s,a)\ \sum_{r\in\mathcal{R}(s,a)}p(s'|s,a)=1
策略
- \pi(a|s),\ \forall s\in\mathcal{S}\ \sum_{a\in\mathcal{A}(s)}\pi(a|s)=1
马尔可夫性质
- 随机过程的无记忆性:
状态价值和贝尔曼方程
- 回报可以评估策略
- 不同轨迹的回报在计算时可构成线性方程组,当前回报取决于其他回报
状态价值
- 随机系统中,回报不能直接衡量策略,因为同一状态开始可以得到不同回报
- 考虑
- t=0,1,2,\cdots
- S_t,\ A_t
- \tau:
- 折回报
- 由于G_t是随机变量,可计算其期望
- 记 v_\pi(s) 为状态价值函数
贝尔曼方程
- 重写G_t
- 重写状态价值
- 上式即为贝尔曼方程,它是一组刻画状态价值之间关系的线性方程
- 等价形式
- 由全概率公式
p(r|s,a)=\sum_{s'\in\mathcal{S}}p(s',r|s,a) \\ p(s'|s,a)=\sum_{r\in\mathcal{R}}p(s',r|s,a) \\
- 得
v_\pi(s)=\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{s'\in\mathcal{S}}\sum_{r\in\mathcal{R}}p(s',r|s,a)[r+\gamma v_\pi(s')]
- 由全概率公式
- 若 r 仅依赖下一个状态 s',则
-
矩阵-向量形式
-
令
\begin{aligned} r_\pi(s)&\overset{·}{=}\sum_{a\in\mathcal{A}}\pi(a|s)\sum_{r\in\mathcal{R}}p(r|s,a)r \\ p_\pi(s'|s)&\overset{·}{=}\sum_{a\in\mathcal{A}}\pi(a|s)p(s'|s,a) \\ \end{aligned} -
则
v_\pi(s_i)=r_\pi(s_i)+\gamma\sum_{s_j\in\mathcal{S}}p_\pi(s_j|s_i)v_\pi(s_j) -
令 v_\pi=[v_\pi(s_1),\cdots,v_\pi(s_n)]^T\in\mathbb{R}^n,\ r_\pi=[r_\pi(s_1),\cdots,r_\pi(s_n)]^T\in\mathbb{R}^n,\ P_\pi\in\mathbb{R}^{n\times n}\ with\ [P_\pi]_{ij}=p_\pi(s_j|s_i),则
v_\pi=r_\pi+\gamma P_\pi v_\pi
-
-
求解(证明略)
-
令
v_{k+1}=r_\pi+\gamma P_\pi v_k,\quad k=0,1,2,\cdots -
则
v_\pi=\lim_{k\rightarrow\infty}v_{k}=(I-\gamma P_\pi)^{-1}r_\pi
-
动作价值
- 定义
- 与状态价值间的关系
- 将上式与贝尔曼方程对比,得
- 更进一步,用动作价值替换上式的状态价值,得
最优状态价值和贝尔曼最优方程
- 强化学习的目标是寻找最优策略,基于最优状态值可以定义最优策略
- 贝尔曼最优方程可用来求解最优状态值和策略
最优策略和最优状态价值
- 当
- 称 \pi^* 为最优策略,v_{\pi^*}(s) 为状态 s 的最优状态价值
贝尔曼最优方程(Bellman optimality equation,BOE)
- 逐元素形式
\begin{aligned} v(s)&=\max_{\pi(s)\in\Pi(s)}\sum_{a\in\mathcal{A}}\pi(a|s)\Bigg[\sum_{r\in\mathcal{R}}p(r|s,a)r+\gamma\sum_{s'\in\mathcal{S}}p(s'|s,a)v_\pi(s')\Bigg],\\ &=\max_{\pi(s)\in\Pi(s)}\sum_{a\in\mathcal{A}}\pi(a|s)q(s,a),\quad s\in\mathcal{S}\\ &\le\max_{a\in\mathcal{A}}q(s,a),\quad \pi(a|s)=\left\{\begin{aligned}&1,\ a=a^*\\&0,\ a\ne a^*\end{aligned}\right.\ \text{时取等} \end{aligned}
- 取贝尔曼方程的矩阵-向量形式,令
- 则最优解
-
求解(由压缩映射原理证明)
-
设 v^* 是 BOE 的一个解,令
v_{k+1}=\max_{\pi\in\Pi}(r_\pi+\gamma P_\pi v_k) -
则
v^*=\lim_{k\rightarrow\infty}v_k -
最优策略为
\pi^*=\argmax_{\pi\in\Pi}(r_\pi+\gamma P_\pi v^*) -
因此
v^*=r_{\pi^*}+\gamma P_{\pi^*}v^*
-
-
最优策略的影响因素
- 当系统模型(p(s'|s,a)、p(r|s,a))固定时,r 和 \gamma 影响最优策略
- \gamma 越小,最优策略越短视,但不会因而走弯路
- 当所有奖励都进行同一仿射变换时,最优策略不变,最优状态价值也是原值的仿射变换
价值迭代与策略迭代
- 求解最优策略的算法
价值迭代
-
步骤
-
策略更新(PU):给定 v_k,求 \pi_{k+1}
\pi_{k+1}=\argmax_\pi(r_\pi+\gamma P_\pi v_k) -
价值更新(VU):给定 \pi_{k+1},求 v_{k+1}
v_{k+1}=r_{\pi_{k+1}}+\gamma P_{\pi_{k+1}}v_k
-
-
算法

策略迭代算法
-
步骤
-
策略评估(PE):给定 \pi_k,求 v_{\pi_k}
v_{\pi_k}=r_{\pi_k}+\gamma P_{\pi_k}v_{\pi_k} -
策略改进(PI):给定 v_{\pi_k},求 \pi_{k+1}
\pi_{k+1}=\argmax_{\pi}(r_\pi+\gamma P_\pi v_{\pi_k})
-
-
算法

截断策略迭代算法
-
比较价值迭代与策略迭代
-
策略迭代
\pi_0\xrightarrow{PE}v_{\pi_0}\xrightarrow{PI}\pi_1\xrightarrow{PE}v_{\pi_1}\xrightarrow{PI}\pi_2\xrightarrow{PE}\cdots -
价值迭代
v_0\xrightarrow{PU}\pi'_1\xrightarrow{VU}v_1\xrightarrow{PU}\pi'_2\xrightarrow{VU}v_2\xrightarrow{PU}\cdots -
对比
 \begin{aligned} &v^{(0)}_{\pi_1} = v_0 \\ \text{value iteration}\leftarrow v_1\leftarrow\ \ &v^{(1)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(0)}_{\pi_1} \\ &v^{(2)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(1)}_{\pi_1} \\ &\ \ \vdots \\ \text{truncated policy iteration}\leftarrow\overline{v}_1\leftarrow\ \ &v^{(j)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(j-1)}_{\pi_1} \\ &\ \ \vdots \\ \text{policy iteration}\leftarrow v_{\pi_1}\leftarrow\ \ &v^{(\infty)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(\infty)}_{\pi_1} \\ \end{aligned}
\begin{aligned} &v^{(0)}_{\pi_1} = v_0 \\ \text{value iteration}\leftarrow v_1\leftarrow\ \ &v^{(1)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(0)}_{\pi_1} \\ &v^{(2)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(1)}_{\pi_1} \\ &\ \ \vdots \\ \text{truncated policy iteration}\leftarrow\overline{v}_1\leftarrow\ \ &v^{(j)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(j-1)}_{\pi_1} \\ &\ \ \vdots \\ \text{policy iteration}\leftarrow v_{\pi_1}\leftarrow\ \ &v^{(\infty)}_{\pi_1}=r_{\pi_1}+\gamma P_{\pi_1}v^{(\infty)}_{\pi_1} \\ \end{aligned}- 价值迭代和策略迭代可以看作是截断策略迭代的两种特殊形式
- 在每步根据当前策略求解状态价值(VU/PE)时,价值迭代只迭代一次,而策略迭代要求迭代到收敛
-
-
截断策略迭代相比策略迭代在策略评估时只进行有限次迭代,但可证明仍能得到最优策略
-
算法

- 优点
- 比价值迭代收敛快,比策略迭代效率高
蒙特卡洛方法
- 无模型强化学习算法
均值估计
- 若用于均值估计的样本之间独立同分布,当 n\rightarrow\infty 时,\overline{x}\rightarrow\mathbb{E}[X],此由辛钦大数定律保证
MC Basic
- 最简单的基于蒙特卡洛方法的强化学习算法
- 在策略迭代算法中,PI 过程需要计算
- 当给定系统模型 \{p(r|s,a),p(s'|s,a)\} 时,
- 当无模型时,取 n 个 episodes,第 i 个 episode 的回报为 g_{\pi_k}^{(i)}(s,a),则
-
算法

- 与策略迭代算法相比,MC Basic 算法不先计算状态价值,而是直接通过样本估计动作价值
- 缺点:采样效率低
-
episodes 长度和奖励对算法的影响
- episode 长度过小,无法抵达能获得正向奖励的状态,估计回报与真实回报偏差过大,导致无法收敛到最优策略
- 奖励过于稀疏,episode 需要很长才能得到正向奖励,导致在状态空间较大时学习效率降低,采取非稀疏奖励可解决这一问题,例如在距离目标较远时可以给予较小的正向奖励
MC Exploring Starts
-
假设有一段轨迹非常长,以至于轨迹中包括了所有状态-动作对很多次,仅对这段轨迹进行采样就可以估计动作价值
-
举例
\begin{aligned} s_1\xrightarrow{a_2}s_2\xrightarrow{a_4}s_1\xrightarrow{a_2}s_2\xrightarrow{a_3}s_5\xrightarrow{a_1}\cdots\quad&[\text{original episode starting from}\ (s_1,a_2)] \\ s_2\xrightarrow{a_4}s_1\xrightarrow{a_2}s_2\xrightarrow{a_3}s_5\xrightarrow{a_1}\cdots\quad&[\text{subepisode starting from}\ (s_2,a_4)] \\ s_1\xrightarrow{a_2}s_2\xrightarrow{a_3}s_5\xrightarrow{a_1}\cdots\quad&[\text{subepisode starting from}\ (s_1,a_2)] \\ s_2\xrightarrow{a_3}s_5\xrightarrow{a_1}\cdots\quad&[\text{subepisode starting from}\ (s_2,a_3)] \\ s_5\xrightarrow{a_1}\cdots\quad&[\text{subepisode starting from}\ (s_5,a_1)] \\ \end{aligned}- 访问一个状态动作之后的轨迹可以看作新的 episode
- 在一个 episode 中,同一状态动作对可能被多次访问,统计所有访问要好于只统计第一次,即使后面的访问与前面相关
-
算法

- 与 MC Basic 相比,不必使用所有 episode 样本估计动作价值,而是直接通过一个 episode 粗鲁估计动作价值后改进策略,逐 episode 迭代
- 即使价值估计得不准确,仍可以向正确的方向更新策略
- 要求初始有足够多的从每个状态-动作对开始的可以遍历所有其他动作对的 episode,真实情况中难以满足
MC \epsilon-Greedy:Learning without exploring starts
- 定义软策略为在任何状态下都有概率采取任何动作的策略
- 算法

- \epsilon-greedy 策略牺牲了利用的准确性,但增强了探索的广度,所有的动作都能很好地访问
- 当 \epsilon 过大时,可能收敛不到最优策略,可以在一开始选择较大值,在迭代过程中逐步减小
随机逼近(Stochastic Approximation)
Robbins-Monro(RM)算法
- 假设要求解下列等式的根
- 其中 w\in\mathbb{R} 是未知变量,g:\mathbb{R}\rightarrow\mathbb{R} 是一个未知函数,我们只能得到 g(w) 的一个带噪声的观测
- 其中 \eta\in\mathbb{R} 是观测误差,可能满足或不满足高斯分布,下面的 RM 算法可对 g(w)=0 进行求解
-
定理:
-
若
\begin{aligned} &(a)\quad 0<c_1<\nabla_wg(w)\le c_2\ \text{for all}\ w;\\ &(b)\quad \sum_{k=1}^{\infty}\alpha_k=\infty\ \text{and}\ \sum_{k=1}^{\infty}\alpha_k^2<\infty;\\ &(c)\quad \mathbb{E}[\eta_k|\mathcal{H}_k]=0\ \text{and}\ \mathbb{E}[\eta_k^2|\mathcal{H}_k]<\infty,\ \ \mathcal{H_k}=\{w_k,w_{k-1},\cdots\} \end{aligned} -
则 w_k 几乎必然收敛于根 w^*,使 g(w^*)=0
-
-
证明略
随机梯度下降(Stochastic gradient descent,SGD)
- SGD 是一种特殊的 RM 算法
- 考虑下列优化问题
- 其中 w 是待优化的参数,X 是随机变量
- 梯度下降算法可以在一些温和的条件下找到最优解
- 求解上式中的 \mathbb{E}[\nabla_wf(w_k,X)] 需要知道 X 的概率分布,但这往往不可得,虽然可以通过大量样本估计期望,但如果样本是逐一取得的,则收集一个样本就更新 w 是有利的,因此算法可修改为
- 上式即著名的随机梯度下算法,随机指算法依赖于独立同分布的随机样本 \{x_k\}
- 特别地,定义 \eta_k=\nabla_wf(w_k,x_k)-\mathbb{E}[\nabla_wf(w_k,X)],SGD 算法可重写为
- 其中 \mathbb{E}[\eta_k]=0
- SGD 可以应用到确定性优化问题中
- 其中 X 是定义在 \{x_i\}_{i=1}^n 上的随机变量,x_k 可以从 X 中随机采样
- 根据每次迭代中选取样本的不同,还可以定义 BGD、MBGD 算法
时序差分方法(Temporal-Difference,TD)
- 增量式无模型算法
状态价值时序差分学习
-
算法
-
给定策略 \pi,算法目的在于估计 v_\pi(s) for all s\in\mathcal{S}。假设 \pi 下有一些样本(s_0,r_1,s_1,\cdots,s_t,r_{t+1},s_{t+1},\cdots)表示时间步,则
\begin{aligned} v_{t+1}(s_t)&=v_t(s_t)-\alpha_t(s_t)\Big[v_t(s_t)-\big(r_{t+1}+\gamma v_t(s_{t+1})\big)\Big],\\ v_{t+1}(s)&=v_t(s),\quad\text{for all}\ s\ne s_t, \end{aligned} -
t=0,1,2,\cdots,v_t(s_t) 是对 v_\pi(s_t) 在 t 时刻的估计;\alpha_t(s_t) 是 t 时刻对于 s_t 的学习率
-
该算法可由 RM 算法推出
-
-
性质分析
\underbrace{v_{t+1}(s_t)}_{\text{new estimate}}=\underbrace{v_t(s_t)}_{\text{current estimate}}-\alpha_t(s_t)\Big[\overbrace{v_t(s_t)-\big(\underbrace{r_{t+1}+\gamma v_t(s_{t+1})}_{\text{TD target}\ \overline{v}_t}\big)}^{\text{TD error}\ \delta_t}\Big]- 在数学上,该算法使得 v_t(s_t) 逐步趋近 \overline{v}_t
- TD error 的期望 \mathbb{E}[\delta_t|S_t=s_t]=0,反映了估计值 v_t 与 v_\pi 间的差异
-
TD 与 MC 对比
- 增量式:在收到经验样本后立刻更新状态/动作价值
- 持续任务:TD 可以处理 episodic 和无限持续的任务
- 自举(Bootstrapping):状态/动作价值的更新依赖先前的估计值,因此 TD 学习需要猜测初始值
- 低估计方差:随机变量较少
动作价值时序差分学习:Sarsa(state-action-reward-state-action)
-
算法
-
给定策略 \pi,算法目的在于估计动作价值,假设在 \pi 下有一些经验样本 (s_0,a_0,r_1,s_1,a_1,\cdots,s_t,a_t,r_{t+1},s_{t+1},a_{t+1},\cdots),t 表示时间步,则
\begin{aligned} q_{t+1}(s_t,a_t)&=q_t(s_t,a_t)-\alpha_t(s_t,a_t)\Big[q_t(s_t,a_t)-\big(r_{t+1}+\gamma q_t(s_{t+1},a_{t+1})\big)\Big],\\ q_{t+1}(s,a)&=q_t(s,a),\quad\text{for all}\ (s,a)\ne(s_t,a_t), \end{aligned} -
t=0,1,2,\cdots,\alpha_t(s_t,a_t) 是学习率,q_t(s_t,a_t) 是对 q_\pi(s_t,a_t) 的估计
-
-
通过 Sarsa 寻找最优策略

动作价值时序差分学习:n-step Sarsa
-
对比
\begin{aligned} \text{Sarsa}\leftarrow\quad G_t^{(1)}&=R_{t+1}+\gamma q_\pi(S_{t+1},A_{t+1}),\\ G_t^{(2)}&=R_{t+1}+\gamma R_{t+2}+ \gamma^2q_\pi(S_{t+2},A_{t+2}),\\ &\vdots\\ \text{n-step Sarsa}\leftarrow\quad G_t^{(n)}&=R_{t+1}+\gamma R_{t+2}+\cdots+\gamma^n q_\pi(S_{t+n},A_{t+n}),\\ \text{MC}\leftarrow\quad G_t^{(\infty)}&=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\cdots,\\ \end{aligned}- G_t=G_t^{(1)}=G_t^{(2)}=G_t^{(n)}=G_t^{(\infty)},各式仅是对 G_t 的不同分解
-
算法
- 假设在 \pi 下有一些经验样本 (s_0,a_0,r_1,s_1,a_1,\cdots,s_t,a_t,r_{t+1},s_{t+1},a_{t+1},\cdots,r_{t+n},s_{t+n},a_{t+n}),则
最优动作价值时序差分学习:Q-learning
-
算法
\begin{aligned} q_{t+1}(s_t,a_t)&=q_t(s_t,a_t)-\alpha_t(s_t,a_t)\Big[q_t(s_t,a_t)-\big(r_{t+1}+\gamma\max_{a\in\mathcal{A}(s_{t+1})}q_t(s_{t+1},a)\big)\Big],\\ q_{t+1}(s,a)&=q_t(s,a),\quad\text{for all}\ (s,a)\ne(s_t,a_t), \end{aligned}- 其中 q_t(s_t,a_t) 是对 (s_t,a_t) 的最优动作价值的估计
- Q-learning 是求解下列动作价值形式的贝尔曼最优方程的随机逼近算法
q(s,a)=\mathbb{E}\big[R_{t+1}+\gamma\max_{a}q(S_{t+1},a)|S_t=s,A_t=a\big]
-
离线策略和在线策略
- 在任何强化学习任务中都存在行为策略和目标策略,行为策略用来生成经验样本,目标策略用来持续更新以收敛至最优策略
- 当行为策略与目标策略相同时,学习过程称为在线策略;不同时,学习过程称离线策略
- Q-learning 是一种离线策略,上述其他 TD 算法都是在线策略
-
离线/在线策略分析
-
Sarsa 是在线策略,考虑 Sarsa 每次迭代需要的样本 (s_t,a_t,r_{t+1},s_{t+1},a_{t+1}),这些样本由下面的过程生成,其中 \pi_b 显然是行为策略,同时,Sarsa 算法目的在于估计目标策略 \pi_T 下 (s_t,a_t) 的动作价值,而更新 \pi_T 需要依赖于样本 (r_{t+1},s_{t+1},a_{t+1}),其中 a_{t+1} 在策略 \pi_b 下生成,因此 \pi_b 也是目标策略
s_t\xrightarrow{\pi_b}a_t\xrightarrow{\text{model}}r_{t+1},s_{t+1}\xrightarrow{\pi_b}a_{t+1} -
Q-learning 是离线策略,Q-learning 求解贝尔曼最优方程,而 Sarsa 求解给定策略下的贝尔曼方程。考虑 Q-learning 每次迭代需要的样本 (s_t,a_t,r_{t+1},s_{t+1}),样本由下面的过程生成,估计 (s_t,a_t) 的最优动作价值依赖于样本 (r_{t+1},s_{t+1}),但样本只受系统模型控制(或只通过与环境交互生成)与 \pi_b 无关
s_t\xrightarrow{\pi_b}a_t\xrightarrow{\text{model}}r_{t+1},s_{t+1}
-
-
在线学习和离线学习
- 在线学习指价值和策略的更新在环境交互的同时进行
- 离线学习指在不与环境交互的情况下,通过经验数据更新价值和策略
- 在线策略算法只可以通过在线学习方式实现,离线策略算法可以通过离线或在线学习实现
-
算法


对比

价值函数方法
值表示:表格到函数
- 假设状态价值不能通过状态检索得到,而需要通过一个含参函数
- 设有 n 个状态 \{s_i\}_{i=1}^n,给定策略 \pi 时相应状态价值为 \{v_\pi(s_i)\}_{i=1}^n,令 \{\hat{v}(s_i)\}_{i=1}^n 是对状态价值的估计,可以通过函数对点集 \{(s_i,\hat{v}(s_i))\}_{i=1}^n 进行近似,下面是一个例子
-
其中,\phi(s)\in\mathbb{R} 称特征向量(feature vector)
-
当检索值时,需要通过函数进行计算,如果函数是一个神经网络,则需要通过前向传播获得输出,函数近似提高了存储效率但是降低了状态值表示的准确性
-
当更新值时,需要通过更新参数向量 w 间接实现,这样会使其他值也得到一定程度的更新
-
当已知 \{v_\pi(s_i)\}_{i=1}^n 时,最优参数向量 w^* 可以通过最小化下列目标函数 J_1 得到
\Phi\overset{·}{=}\left[\begin{matrix}\phi^T(s_1)\\\vdots\\\phi^T(s_n)\end{matrix}\right]\in\mathbb{R}^{n\times2},\quad v_\pi\overset{·}{=}\left[\begin{matrix}v_\pi(s_1)\\\vdots\\v_\pi(s_n)\end{matrix}\right]\in\mathbb{R}^n\\ \begin{aligned} J_1=\sum_{i=1}^n\big(\hat{v}(s_i,w)-v_\pi(s_i)\big)^2&=\sum_{i=1}^n\big(\phi^T(s_i)w-v_\pi(s)i)\big)^2\\ &\overset{·}=||\Phi w-v_\pi||^2 \end{aligned}- 该最小二乘问题的解为
w^*=(\Phi^T\Phi)^{-1}\Phi{v_\pi}
- 该最小二乘问题的解为
基于函数近似的状态价值时序差分学习
- 目标,其中期望是关于随机变量 S\in\mathcal{S} 的
- 优化,使用梯度下降算法
- 将系数合并,并应用随机梯度,得下式,其中 s_t 是 S 在 t 时刻的样本
-
上式中 v_\pi(s_t) 是不可知的,因此需要估计,根据之前的算法,可有
-
MC:假设有 episode (s_0,r_1,s_1,r_2,\cdots),令 g_t 为 s_t 开始的回报,则
w_{t+1}=w_t+\alpha_t\big(g_t-\hat{v}(s_t,w_t)\big)\nabla_w\hat{v}(s_t,w_t) -
TD:通过 r_{t+1}+\gamma\hat{v}(s_{t+1},w_t) 近似 v_\pi(s_t),得
w_{t+1}=w_t+\alpha_t\big(r_{t+1}+\gamma\hat{v}(s_{t+1},w_t)-\hat{v}(s_t,w_t)\big)\nabla_w\hat{v}(s_t,w_t)
-
-
当 \hat{v} 是线性函数时 \hat{v}(s,w)=\phi^T(s)w,通过 TD 求解给定策略下的状态价值,简称 TD-Linear

基于函数近似的动作价值时序差分学习
- 函数近似的 Sarsa 算法,假设 q_\pi(s,a) 通过 \hat{q}(s,a,w) 进行近似,则
- 算法

- 函数近似的 Q-learning 算法
- 算法

- 在上述两个算法中,虽然值使用函数表示,但策略还是表的形式,仍假定有限个状态和动作
Deep Q-learning
- deep Q-learning 或称 deep Q-network(DQN)是最早且最成功的深度强化学习算法之一,算法使用策略 \pi_b 下的一些经验样本近似最优动作价值,通过最小化下列目标函数实现
- 其中 (S,A,R,S') 是随机变量,分别表示一个状态、动作、即时奖励和下一个状态,上式可看作是动作价值形式贝尔曼最优方程的平方误差
- 为简便计算,假定 R+\gamma\max_{a\in\mathcal{A}(S')}\hat{q}(S',a,w) 中的 w 在短时间内固定。引入主网络 \hat{q}(s,a,w),目标网络 \hat{q}(s,a,w_T),目标函数变为
- 梯度为
- 算法
-
将 w 和 w_T 设为相同的初始值,收集一些经验样本,存储在一个称为回放缓冲区的数据集 \mathcal{B}\overset{·}{=}\{(s,a,r,s')\} 中,每次迭代,从 \mathcal{B} 中选择小批量样本来更新主网络。更新主网络的参数 w 时并非显示地使用梯度,而是通过训练神经网络,因此使用小批量样本而不是单个样本来更新主网络是深度和非深度强化学算法的一个显著区别。每隔一定迭代次数,将目标网络设置为与主网络相同以满足 w_T 在计算梯度时固定的假定
-
上述使用缓冲区的技术称为经验回放(experience replay),从回放缓冲区取样本要满足均匀分布,这是为了更好地定义 DQN 的目标函数,因为 S,A,R,S' 需要满足某一分布,最简单的方式就是使用均匀分布,但实际中,状态-行为样本可能不满足均匀分布,因为这些样本来自按行为策略生成的样本序列,为此可以通过经验回放打破样本之间的关联,并使其满足均匀分布。经验回放的另一个好处是提高了数据利用率,因为同一样本可被多次采样

-
策略梯度方法
- 将策略也用函数的形式表示,\pi(a|s)\rightarrow\pi_\theta(a|s)
- 策略函数化后,通过优化某些标量可以得到最优策略,这类方法称策略梯度,与前几章基于价值的方法相比,策略梯度可以更高效地处理大规模的状态-动作空间,样本利用也更高效
策略的函数表示
- 最优策略可通过基于梯度的算法最优化指标得到
定义最优策略的指标
-
平均状态价值 \overline{v}_\pi
\overline{v}_\pi=\sum_{s\in\mathcal{S}}d(s)v_\pi(s)-
将 d(s) 解释为 s 的概率分布,该指标可写为
\overline{v}_\pi=\mathbb{E}_{S\sim d}[v_\pi(S)] -
d 通常选择 \pi 下的平稳分布 d_\pi,最终目标是使 \overline{v}_\pi 最大,\overline{v}_\pi 有两种重要的等价形式
-
经验奖励形式,假设在 \pi(\theta) 下收集到奖励 \{R_{t+1}\}_{t=0}^\infty
J(\theta)=\lim_{n\rightarrow\infty}\mathbb{E}\Bigg[\sum_{t=0}^n\gamma^tR_{t+1}\Bigg]=\mathbb{E}\Bigg[\sum_{t=0}^\infty\gamma^tR_{t+1}\Bigg]=\overline{v}_\pi -
向量内积形式,v_\pi=[\cdots,v_\pi(s),\cdots]^T\in\mathbb{R}^{|\mathcal{S}|},\ d=[\cdots,d(s),\cdots]^T\in\mathbb{R}^{|\mathcal{S}|}
\overline{v}_\pi=d^Tv_\pi
-
-
平均一步奖励(平均奖励)\overline{r}_\pi
\overline{r}_\pi\overset{·}{=}\sum_{s\in\mathcal{S}}d_\pi(s)r_\pi(s)=\mathbb{E}_{S\sim d_\pi}[r_\pi(S)] \\r_\pi(s)\overset{·}{=}\sum_{a\in\mathcal{A}}\pi(a|s,\theta)r(s,a)=\mathbb{E}_{A\sim\pi(s,\theta)}[r(s,A)|s]\\r(s,a)\overset{·}{=}\mathbb{E}[R|s,a]=\sum_rrp(r|s,a)- 经验奖励形式,假设在 \pi(\theta) 下收集到奖励 \{R_{t+1}\}_{t=0}^\infty
J(\theta)=\lim_{n\rightarrow\infty}\frac{1}{n}\mathbb{E}\Bigg[\sum_{t=0}^{n-1}R_{t+1}\Bigg]=\overline{r}_\pi
- 向量内积形式,r_\pi=[\cdots,r_\pi(s),\cdots]^T\in\mathbb{R}^{|\mathcal{S}|},\ d_\pi=[\cdots,d_\pi(s),\cdots]^T\in\mathbb{R}^{|\mathcal{S}|}
\overline{r}_\pi=d^T_\pi r_\pi
- 经验奖励形式,假设在 \pi(\theta) 下收集到奖励 \{R_{t+1}\}_{t=0}^\infty
指标的梯度
-
J(\theta) 的梯度
\nabla_\theta J(\theta)=\sum_{s\in\mathcal{S}}\eta(s)\sum_{a\in\mathcal{A}}\nabla_\theta\pi(a|s,\theta)q_\pi(s,a)-
其中 \eta 是状态分布,上式可以写为期望形式
\begin{aligned} \nabla_\theta J(\theta)&=\mathbb{E}_{S\sim\eta}\Bigg[\sum_{a\in\mathcal{A}}\nabla_\theta\pi(a|S,\theta)q_\pi(S,a)\Bigg]\\ &=\mathbb{E}_{S\sim\eta}\Bigg[\sum_{a\in\mathcal{A}}\pi(a|S,\theta)\nabla_\theta\ln\pi(a|S,\theta)q_\pi(S,a)\Bigg]\\ &=\mathbb{E}_{S\sim\eta,A\sim\pi(S,\theta)}\Big[\nabla_\theta\ln\pi(A|S,\theta)q_\pi(S,A)\Big] \end{aligned} -
J(\theta) 可以是 \overline{v}_\pi^0=d_0^Tv_\pi,\ \overline{v}_\pi,\ \overline{r}_\pi,其中 d_0 与 \pi 独立,对应 \eta 分别为 \rho_\pi,\ d_\pi,\ d_\pi,其中 \rho(s)\overset{·}{=}\sum_{s'\in\mathcal{S}}d_0(s')\text{Pr}_\pi(s|s'),\ \text{Pr}_\pi(s|s')=\sum_{k=0}^\infty\gamma^k[P_\pi^k]_{s's}]=[(I-\gamma P_\pi)^{-1}]_{s's},\overline{r}_\pi=(1-\gamma)\overline{v}_\pi,证明略
-
\pi(a|s,\theta),必须对所有 (s,a) 为正,因此可以选取 softmax 函数,h(s,a,\theta) 反映状态 s 下选择 a 的偏好程度
\pi(a|s,\theta)=\frac{e^{h(s,a,\theta)}}{\sum_{a'\in\mathcal{A}}e^{h(s,a',\theta)}},\quad a\in\mathcal{A},
-
-
当不使用折回报时
-
定义
\begin{aligned} v_\pi(s)&\overset{·}{=}\mathbb{E}[(R_{t+1}-\overline{r}_\pi)+(R_{t+2}-\overline{r}_\pi)+\cdots|S_t=s],\\ q_\pi(s,a)&\overset{·}{=}\mathbb{E}[(R_{t+1}-\overline{r}_\pi)+(R_{t+2}-\overline{r}_\pi)+\cdots|S_t=s,A_t=a],\\ \end{aligned} -
则对 \overline{r}_\pi 求梯度的结果为
\nabla_\theta\overline{r}_\pi=\mathbb{E}_{S\sim d_\pi,A\sim\pi(S,\theta)}\Big[\nabla_\theta\ln\pi(A|S,\theta)q_\pi(S,A)\Big] -
证明略
-
蒙特卡洛策略梯度(REINFORECE)
- 最大化 J(\theta) 的梯度上升算法,应用上述梯度公式
- 但上式中的梯度是不可知的,通过随机梯度方法得到下列算法
- 其中 q_t(s_t,a_t) 是对 q_\pi(s_t,a_t) 的近似,如果 q_t(s_t,a_t) 通过蒙特卡洛估计得到,称上述算法为蒙特卡洛策略梯度,将对数部分展开,得
- 随机变量 S 和 A 的选取往往不遵循上述式中的分布,因为对样本的利用效率较差
- 算法
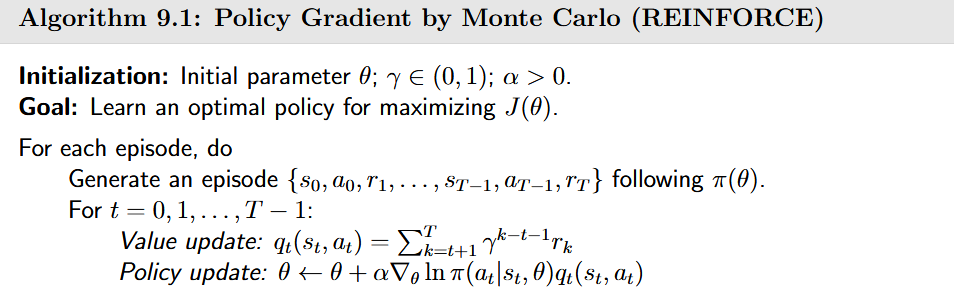
Actor-Critic 算法
- Actor 指策略更新步骤,因为其动作遵循策略,critic 指价值更新步骤,因为其通过相应的价值来批评行动者,A-C 算法是一种策略梯度算法
Q actor-critic (QAC)
- 最简单的 A-C 算法
- 在策略梯度方法中,使用基于函数近似的Sarsa算法估计动作价值,算法为

Advantage actor-critic(A2C)
- 策略梯度目标函数的梯度的特殊性质,令 b(S) 为基线,则
- 因为 \mathbb{E}_{S\sim\eta,A\sim\pi}\Big[\nabla_\theta\ln\pi(A|S,\theta)b(S)\Big]=\sum_{s\in\mathcal{S}}\eta(s)b(s)\nabla_\theta\sum_{a\in\mathcal{A}}\pi(a|s,\theta_t)=0
- 因为需要通过随机样本 x 来估计 \mathbb{E}[X],X 的方差越小越好,因此可以通过调整基线来最小化 \text{var}(X),可证明,最优的基线为
- 但上式对于现实情况过于复杂,可将权重向忽略,得到次优解
- 更新梯度上升算法
- 其中 \delta_\pi(S,A)\overset{·}{=}q_\pi(S,A)-v_\pi(S) 称优势函数,反映了选择动作 A 相比其他动作的优势
- 取随机梯度版本
- 使用 TD error 近似 \delta_t
- 算法

离线策略 actor-critic
- 上述 REINFORCE,QAC,A2C 都是在线策略算法,因为 \pi(\theta) 既是行为策略又是目标策略
重要性采样
- 假设随机变量 X\in\mathcal{X},需要通过一些样本 \{x_i\}_{i=1}^n 估计 \mathbb{E}_{X\sim p_0}[X]
-
假设样本遵循 p_0 生成,则可直接通过样本均值进行估计
-
假设样本遵循 p_1 生成,可通过重要性采样技术进行估计,具体而言
\mathbb{E}_{X\sim p_0}[X]=\sum_{x\in\mathcal{X}}p_0(x)x=\sum_{x\in\mathcal{X}}p_1(x)\underbrace{\frac{p_0(x)}{p_1(x)}}_{f(x)}x=\mathbb{E}_{X\sim p_1}[f(X)] -
令 \overline{f}\overset{·}{=}\frac{1}{n}\sum_{i=1}^{n}f(x_i),则
\mathbb{E}_{X\sim p_0}[X]\approx\overline{f}=\frac{1}{n}\sum_{i=1}^n\underbrace{\frac{p_0(x_i)}{p_1(x_i)}}_{\text{importance weight}}x_i
-
离线策略的策略梯度
- 目标函数,其中 d_\beta 是策略 \beta 下的平稳分布
- 梯度
- 同 A2C 中的做法,将梯度优化为
- 参数更新算法为
- 算法

确定性 actor-critic
- 略
评论区