



NSDI 24
分布式,共享链路的通信竞争
引入
随着GPU算力规模上升,DML通信占大量训练时间,当前工作没有考虑
CASSINI降低网络拥塞,无需硬件支持/修改拥塞控制协议
通过偏移延迟迭代,交错编排计算与通信
用亲和图抽象作业通信,通过图遍历搜索偏移量
背景和动机
分布式训练流量模式
场景:大规模集群多种分布式任务
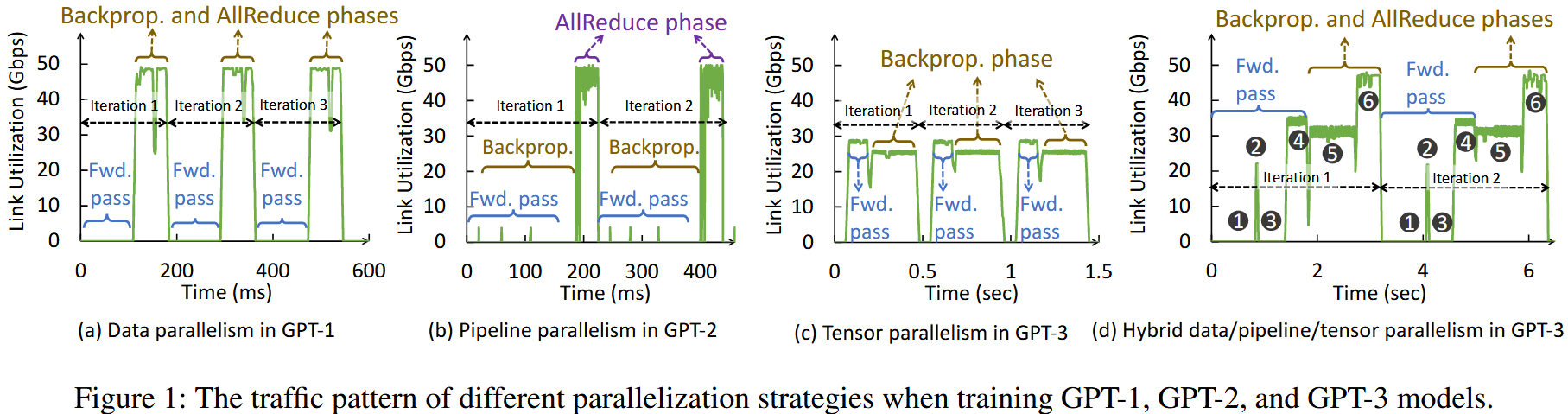
数据并行DP
前向阶段无通信
流水线并行PP
垂直划分模型,通过PipieDream划分批次为微批次,微批次激活参数需要少量通信
张量并行
水平划分模型,前反向都有大量通信流量
混合并行
结合数据、流水线、张量并行
核心发现
训练参数不变,通信模式重复
Up和Down阶段取决于并行策略和超参
Up、Down阶段交错
考虑带宽竞争,增强调度器功能
通过兼容性评分量化可交错程度
几何抽象
训练 ——> 圆周,通信 ——> 圆周上的一段
不同任务Up、Down阶段交错 ——> 旋转圆周
旋转 ——> 延迟作业启动
最优交错方案 ——> 旋转,使得链路上所有角度的带宽需求总和低于链路带宽
捕获不同迭代时间的任务
圆周长为任务迭代周期公倍数
捕获模型并行任务带宽需求
圆周上不同段用颜色表示不同程度的需求
寻找旋转角度
用最优化方程寻找每个任务的最优角度
输入:一组链路上竞争作业的集合
优化目标与输出:
目标:最大化兼容性得分
输出:每个作业的旋转角度
约束条件
各角度带宽需求和不超过限制
角度在0到2π/rj
增量ML调度器
亲和图
挑战
如果任务跨多条链路,只能选择一个旋转角度
方法
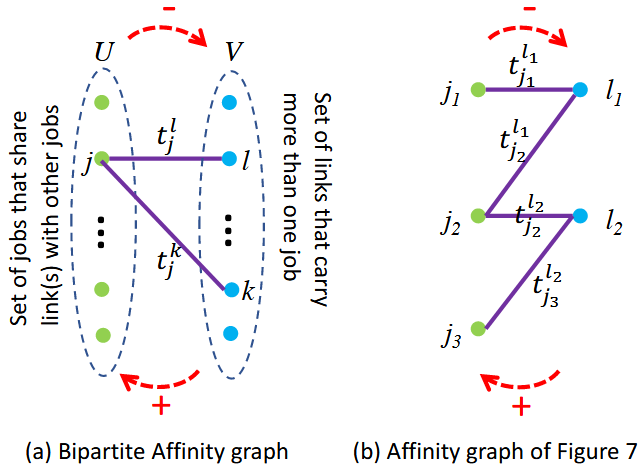
使用二分亲和图映射任务集和链路集
通过修改的BFS遍历图获得所有作业的唯一时间偏移
与现有调度器结合
略
实验
略
评论区