



EuroSys 24
算子粒度调度,HP+BE
面向固定应用
引入
背景
GPU比CPU吞吐量高几个数量级,高利用率使用GPU节能且节省开销
问题
LC推理任务以小批量来满足SLO,并行度低;训练任务最大批量受限且受数据处理或通信瓶颈影响,都导致利用率低
分析
DL负载由一系列数据依赖算子组成,各自有不同的计算和内存需求
总会有某种类型资源闲置,吞吐量和带宽利用率呈爆发式,平均利用率低
解决
GPU共享
当前GPU共享问题
时分共享以推理或一个训练批次为粒度,调度需等待GPU上任务完成,产生队头阻塞
空分共享粒度过粗或无法充分感知任务干扰
Orion
拦截内核启动启动请求,算子粒度,充分利用HP微秒级空闲的计算和内存资源
GPU架构背景
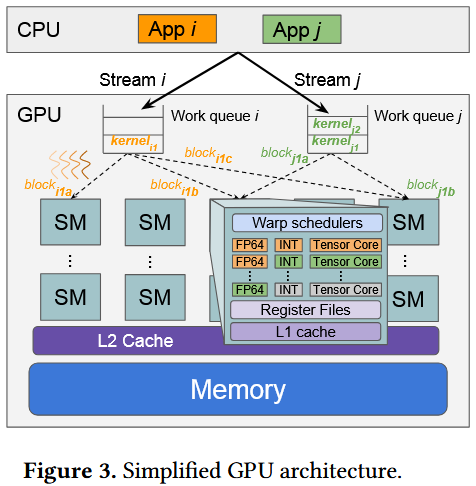
编程抽象
DL框架将卷积等运算编译后作为CUDA内核提交到GPU,同时进行显存、内存管理
应用将内核启动和内存操作关联到一个CUDA流,流是按序执行的操作序列
GPU硬件调度
如图3
当SM上的某项资源被占满后,停止调度线程束
GPU利用率指标
SM利用率
忙碌SM占比,但只要SM某一部分资源在使用即为忙碌,粒度粗
计算吞吐量利用率
SM计算单元的利用率(激活时间占比)
显存利用率
已分配显存占比
显存带宽利用率
峰值显存带宽占比
DNN的GPU利用率
受限于CPU、通信、组调度等瓶颈,利用率普遍较低
除上述原因,批量大小同时影响GPU利用率、训练效率、训练指标
LLM推理解码阶段访存密集,不能高利用计算资源
实例分析
所有负载计算吞吐量利用率和显存带宽利用率呈突发性波动,平均利用率低,尽管SM利用率较高
计算吞吐量利用率和显存带宽利用率峰值在时间上交错
大部分内核为计算密集或访存密集,无法同时占满两类资源导致闲置
GPU内核协同
单个作业内核有顺序依赖
跨作业可以协同调度资源密集型互补的内核,可以提高利用率且最小化干扰
GPU共享相关工作
时间共享
多任务间GPU上下文切换实现
现有系统仍依赖单任务串行执行,导致计算资源浪费
空间共享
MIG粗粒度分区不灵活,模型需要检查点恢复
MPS自由共享计算、存储和缓存资源,干扰大
略,都未考虑内核密集型协同调度
Orion
面向HP + BE,通过DLL形式实现
拦截GPU操作根据离线剖析进行调度后提交执行,支持分布式
调度器
针对闭源GPU,不考虑内核在SM中的分布控制和抢占
客户端形式实现
内核调度策略
轮询多客户端队列,直接提交HP内核到HP流
离线剖析BE内核的计算/显存资源、SM利用率和执行时长,当无PH或BE规模小且与PH内核互补时调度
根据PH吞吐量二分搜索BE内核的SM阈值,对于未知内核,直接乐观执行
BE内核只在未完成BE内核总预期耗时小于HP任务请求延迟(推理)或迭代周期(训练)时启动,避免长时间执行导致HP饥饿
实现机制
GPU流优先级
优先调度HP流的新内核,因为不保证BE流内核被抢占
CUDA事件
监控GPU流进度而无需流同步操作
内存管理
内存操作(拷贝、分配)只消耗CPU-GPU带宽,与内核调度分离,直接提交
内存操作可以考虑竞争来优化
对于内存分配等设备同步操作,同步所有客户端避免无效内存访问
与上层集群调度器正交,假设已选择与显存合适的任务共置运行
负载剖析
任务执行前离线剖析:
各内核计算吞吐量、内存吞吐量和执行时间
SM需求
HP任务请求延迟(单批推理/一轮训练)
DL框架集成
框架无感知,通过动态链接集成,对用户透明
Pytorch原型
通过封装CUDA内核启动和高性能库中的必要函数,将信息提交到客户端队列
评估
方法论
负载
经典DL负载
共置模式
1 HP推理 + 1 BE训练
1 HP训练 + 1 BE训练
1 HP推理 + 1 BE推理
请求到达模式
推理
均匀分布、泊松分布
平均到达率:匹配MAF前20常见应用
Apollo trace:视觉模型
PH使用时间戳,共置的BE均匀分布
训练
闭环提交
Baseline
简单时分
MPS
GPU Streams
REEF-Nvidia
Tick-Tock
Ideal
指标
PH推理:p99延迟
总吞吐量
实验
略,感觉有很多不合理的实验和分析
性能分析拆分
给一个baseline逐渐增加Orion的优化模块,测试HP推理p95延迟变化
缺陷
需要作业剖析,几十毫秒级的推理任务需要对每个内核进行2-5秒的离线剖析
只适用于ML应用场景,模型固定,在作业无感知情况下不可行
评论区