



ASPLOS 25
无服务器计算(SLC)
引入
背景
SLC在DL服务中应用广泛
推理和弹性训练整合在无服务器架构中,能节约资源、部署自动、弹性扩容
LLM带动GPU无服务器DL系统更加流行
问题
GPU碎片利用导致低资源利用率、高开销,削弱了SLC的弹性、成本优势
现有方法
独占式显著浪费资源
MPS等配额共享不灵活
按需共享可充分利用SLC的优势
Dilu
内省弹性按需调度,水平(实例间调节容)+垂直(实例内计算内核增减)
挑战:精确资源需求剖析、QoS、异构负载、竞争性能干扰
贡献
高效二分式训练任务GPU资源剖析,混合增长型推理任务搜索策略(3.3xSOTA)
QoS下的资源互补调度算法,减少碎片提高GPU利用率和函数部署密度
快速垂直调节+懒水平调节,二维弹性,降低冷启动率,维持服务违约率
Kubernetes/Docker集成,集群表现优异
背景和动机
无服务器深度学习服务
无服务器训练
即用型在线训练,自动化部署训练工作流,训练工作节点弹性扩容
无服务器推理
在线服务,负载波动大,天然适用SLC
注重时效
趋势
SLF模型规模更大,更受计算资源限制
粗粒度GPU资源配置限制SLC性能
GPU资源
GPU设备
Forward、Backward计算密集,梯度同步访存密集
LLM推理,Prefilling计算密集,Decoding访存密集
高层次的调度可能导致特定GPU资源利用率不足
云GPU分配
独占式分配,利用率低
GPU共享
基于MPS的空分、时-空分复用、虚拟GPU、时间片轮转等
workloads波动时,调整开销大,实例资源静态分配,无法即时处理突发负载
缺少细粒度GPU供给
SLC中的GPU资源碎片
当前的弹性机制易产生大量碎片
观察
GPU资源过度配置
静态GPU分配,资源易过度配置来确保SLO,资源请求=资源上限
SLC下GPU闲置
分布式训练的通信阶段,GPU计算资源闲置(20% ~ 40%),并行策略导致大量气泡
SL推理任务保留策略
通过保留机制平衡冷启动开销,保留的推理函数长时间内仅有少量调用,大量浪费资源
影响
GPU碎片与分配限制,降低SLF的弹性和部署密度
增加用户和提供商的成本
因此有必要建立按需分配GPU资源的无服务器深度学习服务机制
动机和挑战
洞察:内省弹性
按需提供细粒度、持续自适应的GPU资源
内核级负载实时动态复用实例间的GPU碎片,最大化GPU利用率
要求
识别静态GPU碎片
高效复用多种负载产生的动态碎片
相互协调应对突发负载
初步验证
协同(3卡训/推)比独占(4卡3训1推)大幅提高推理吞吐量,且保障QoS,共置的训练任务吞吐量小幅下降
挑战
保障QoS需要的GPU资源配额难以准确估计
DL训推的多样性使性能剖析采样空间复杂
需要调度策略复用碎片并高效共置负载
负载波动和集群资源动态变化大幅增加搜索空间,调度策略难以达成多种目标
需要设计跨层次协同机制解决共置任务竞争问题
否则产生大量SLO违约和性能退化
系统设计
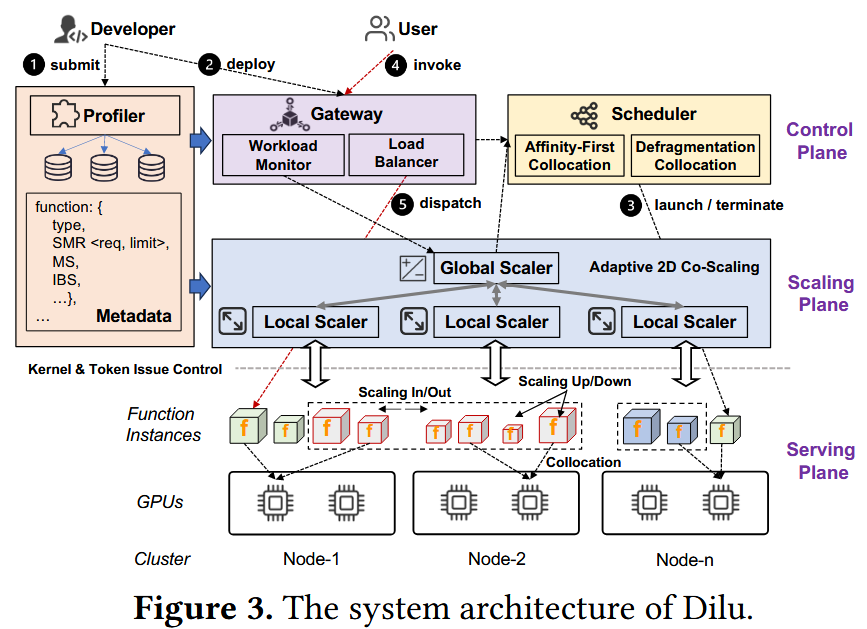
架构概览
控制面
用户提交程序函数、QoS描述
分析器通过剪枝搜索获得资源计划,提交函数到网关
经网关再提交到调度器,调度器根据多种原则部署DL任务实例
调节面
自适应2D内省弹性按需GPU资源配置
全局调节器:通知调度器进行函数实例启动/终止(水平)
局部调节器:通过SM配额调节函数计算资源来保障QoS并提高GPU利用率(垂直)
负载波动时,水平/垂直联合调节
服务面
函数以实例形式共享GPU,或跨服务器以支持LLM
多因子剖析
因子:SMR(SM使用率)、显存、IBS(推理bs)
SMR配额,可调节
[ 请求,限制 ]
请求:保障QoS(训练吞吐量/推理SLO)所需的最少计算资源
限制:突发推理负载下保障QoS或接近独占训练吞吐量所需的最少计算资源
显存:固定
训练剖析
通过二分法根据剖析吞吐量搜索SMR
80%吞吐量作为请求配额
100%吞吐量作为限制配额
推理剖析
搜索迭代时,IBS加倍,SMR线性增
寻找保障QoS时,吞吐效率(吞吐量/SMR)最高的 <IBS, SMR> 对作为请求
请求的两倍作为限制
剖析效率
优于baseline
资源互补调度
最优化问题(NPC)
变量:各任务分配
目标:最少GPU占用数
条件:寻找满足所有QoS且所有卡不超显存
贪心策略
亲和性优先(减少多实例函数的短板效应)
资源互补,按下列顺序分配
高亲和GPU中共置碎片(SM碎片和显存碎片加权和)最小
非高亲和GPU中共置碎片最小
新未占用的GPU
平衡超订和QoS
总请求不超过配额
总限制不超过配额*1.5
自适应2D调节
应对波动负载、冷启动
动态快速垂直调节
通过内核拦截与令牌(周期内可执行GPU时间)调节实例的内核发送速率
监控单次迭代内的内核启动周期KLC
KLC显著增加时快速增加发放令牌数,同时临时减少共置实例令牌数
近期未启动内核,自动缩减;共置实例长期空闲,自动增加
懒水平调节
仅横向或基于历史预测的保留策略,由于短期不可预测会产生显著冷启动开销与大量SLO违约
优先快速垂直调节避免秒级突发请求引起冷启动,延缓水平扩容
必须水平扩容时,通过滑动窗口指导动态增/减实例
系统实现
原型
Kubernetes+Docker,Python+C
剖析器:通过MPS给DLF镜像分配不同资源
调节器:Unix domain socket + CUDA Interception Library
评估
方法论
物理集群:5节点k8s集群,单节点4张A100
负载:主流CV、NLP小到LLM模型
训练:中小规模DDP,LLM使用DeepSpeed
到达模式:泊松、伽马、MAF轨迹
模拟集群:1000节点
指标:吞吐量、p50/99延迟、SLO违约率SVR、冷起动次数CSC、LLM推理token输出速度
Baseline
GPU层次
独占
MPS
FaST-GS
TGS
集群层次
独占
FaST-GS+
INFless+
性能表现
略,见论文
评论区