



TPDS 25
服务器负载(SW)+无服务器函数(SLF)共置
引入
背景
DL在多领域性能优异,GPU集群广泛部署且未来会不断扩大
问题
多组户GPU集群利用率低,原因:
资源分配方式问题
分布式DL资源利用特性问题
分析
多数DL任务无法占满SM,MIG等分割GPU的方法粒度太粗
分布式训练的通信和同步成为瓶颈,大部分时间在等待网络传输
现有研究问题
将GPU视为不可分割
局限于特定类型负载
未针对DL场景
新思路
无服务器计算能够细粒度分配资源
无服务器计算现有问题
未能有效利用GPU,因为GPU隔离机制不成熟
分析(挑战)
共置SLF和SW时
计算资源竞争导致性能下降(10%),增加共置负载数量严重影响性能
性能下降导致SLF服务SLO(截止时间)问题
冷启动问题,启动时间远超执行时间
SMORE
SLF利用闲置GPU资源
目标
向SW中共置SLF,满足SLF的SLO情况下提升GPU利用率,同时最小化性能影响
贡献
首个无服务器架构DL集群GPU利用率优化框架
性能退化预测算法,少量样本高精度
退化感知调度算法
负载共置特性分析
分析训-推任务共置时的GPU利用率
分析步骤
方法论
步骤
独立执行每个负载
选低、中、高三个利用率等级的训练负载分析
将训练负载与推理函数共置执行
模型
开源数据集+经典模型
指标
SM利用率
推理函数P99延迟
训练负载epoch耗时
环境
略
观察结果
DL模型资源需求有差异,同模型SM利用率在特定区间(粒度很粗?)
共置的训-推组合不同,性能退化程度也有差异
随推理请求数增加,两类工作负载性能衰退同时增加,可以通过建模预测退化
推理任务的冷启动(GPU上下文初始化、框架初始化、模型加载等)时间大于推理时间,可能导致无法满足SLO
应有的实现
控制性能衰退
满足SLF的SLO
避免冷启动显著开销
设计概述
将训练任务视为SW,推理函数部署为SLF以确保满足SLO
预测性能衰退,辅助调度器进行函数请求准入控制
退化感知调度算法,动态选择共置组合,以尽量满足SLO
请求量预测,通过预加载/卸载处理冷启动问题
具体流程
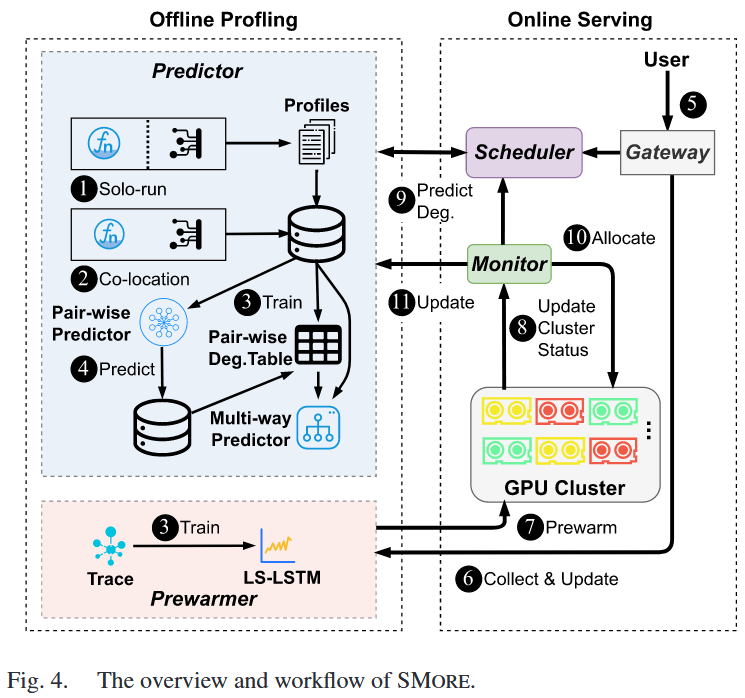
共置性能退化预测器
设计
离线-在线配对+多路预测器
预测一个SW和N个SLF共置时的性能退化
成对共置性能剖析
考虑一个SW与一个SLF共置,监控性能指标(SM util + Mem util)
输入:将两类负载的特征(浮点运算次数、各种层数等)
目标:性能衰退程度
模型:随机森林+RMSLE
多路共置预测
公式有笔误且文字描述不清
大概是将1+1的情况加系数指数扩展为1+N的情况,通过输入和目标调整系数
性能退化感知调度算法
目标:提升GPU利用率,满足SLF的SLO,控制性能退化
性能退化感知函数调度
任务优先级
混合调度策略
低负荷时,最小化性能退化
高负荷时,寻找可行放置
调度策略
按优先级处理任务,从GPU池采样m个计算退化
高负荷时选择第一个满足退化阈值的
低负荷时选择退化最小的
预热
混合LSTM管理冷启动
SLF的冷启动包括资源分配、初始化、库加载、GPU上下文初始化、模型加载等,开销显著
通过LS-LSTM根据请求时间序列预测何时预热函数运行时,何时终止函数运行时
LSTM预测请求数,离-在线训练
输入:前n分钟请求数
输出:下一分钟请求到达数
冷启动反映指标
资源浪费率:资源加载完到开始执行的时间 / 总时间
冷启动率:发生冷启动的函数数 / 函数总数
预热控制
根据预测的到达数,预加载DL模型
实际数量达到预测数量,释放容器,减少浪费
实现
略
评估
单机八卡3090
自制负载
MAF轨迹,放缩到达率,延迟SLO随机设置为P99延迟1到4倍
略,baseline不够好且没看出比baseline强多少
评论区