



TACO 25
作业打包
引入
背景
GPU集群成为DL基础设施,好的调度器提升集群效率
任务打包是提升集群利用率的关键
问题
当前打包策略过于保守
仅打包低干扰任务,否则性能严重退化
仅打包GPU需求相同的任务,否则出现Stragger拖慢整体训练
LLM广泛应用,保守打包策略无法灵活应对小大模型混部场景
分析
当前调度器只关注作业级资源分配与打包决策,缺少对任务打包执行时负载平衡等的细粒度调整
Gimbal
集群调度器和硬件之间的中间件
通过两个校准原语,细粒度协调本地打包作业的执行,支持多种调度目标
非侵入,无需修改代码
贡献
保守原因在于集群调度与作业打包之间的范围和粒度不匹配
细粒度协调机制放宽了作业打包的保守性,从而挖掘出提升集群效率的作业打包潜力
校准原语通用可拓展,支持多种调度目标
效果好
背景和动机
DL调度
筛选资源需求互补的任务协同调度
释放打包潜力
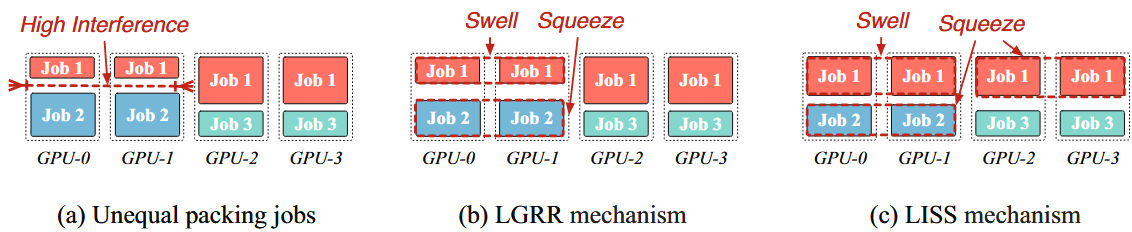
以往算法仅打包干扰可忽略且GPU等资源需求一致的任务,保守
自由竞争(共置任务无资源限制)下的共置导致性能下降,使用MPS限制某个任务资源后整体JCT可能降低
DL任务随机到达,最优打包方案需要逐步搜索
对于不均衡打包中的straggler,需要细粒度调节批次等进行均衡
调度和打包的范围和粒度不匹配
调度集群级,打包任务级,需要在局部细粒度调整
架构总览
架构
运行时监控,worker校准器,激进的打包协调器(策略需根据目标制定)
工作流
在上层任务打包策略分配共置任务到GPU后,根据运行时信息协调执行过程,以适配上层打包策略的目标
任务打包校准
校准原语与机制
校准原语
针对两任务A、B共置后,A受B影响性能退化严重,限制B的资源可缩短平均JCT
worker.squeeze,某工作节点训练速度需要降低
worker.swell,某工作节点训练速度需要提高
实现机制
LGRR,底层GPU资源限制
通过MPS,限制worker线程资源,调整粒度为10%GPU总资源
LISS,输入样本窃取
借鉴LB-BSP,快速节点从慢速节点窃取样本(32 : 32 —> 48 : 16)
校准应用
映射原语到执行机制
压缩/扩张当前任务指定的N个工作节点,通过LGRR调整资源,再通过LISS消除可能出现的stragglers
压缩N个工作节点,扩张M个工作节点,适用作业内工作节点性能差异显著场景,通过LISS重分配样本均衡负载
协调例子
优势
解耦,通过校准原语构建策略,无需关注底层
可以细粒度动态调整,无需重启任务,灵活
激进的作业打包
打包限制
仅允许两个任务打包
拓扑保障
忽视拓扑关系进行分配会产生级联影响
小GPU规模的任务可与大规模任务共置,同规模任务只进行均衡共置
协调策略构建
通过设置局部目标函数和优先级函数,达成总体目标
局部目标和作业优先级
JCT:略
DDL:略
makespan:略
搜索算法(?论文描述不清)
集群中已打包的作业构成独立的作业集
作业集内
按GPU规模划分作业集为两部分,最大规模任务和其他,其他任务集为高优先级
扩张高优先级工作节点,三次无效后退出
压缩低优先级工作节点,如果Jmax属于低优先级且有straggler,同时压缩高优先级工作节点,三次无效后退出
实现
通过上下文池实现低开销资源限制
Pytorch仅支持向主CUDA上下文(100%资源)提交内核
重写CUDA上下文管理,动态创建上下文实现细粒度资源控制
校准时新建上下文并删除旧上下文,需要200MB开销维持上下文池
窃取输入样本的采样器
拓展Pytorch数据采样器,根据全局信息动态调整数据分配
实验
略
评论区