




引入
大规模分布式训练大模型时,检查点的读写成为瓶颈,高频加剧训练阻塞与带宽占用,低频导致高重启代价,容错训练需要根据资源动态弹性变化
主要挑战:
准确故障感知和作业恢复
I/O性能瓶颈影响检查点写入,保存策略影响训练耗时
现有弹性训练系统缺乏复杂场景下的自动恢复机制
贡献:
准确高效的容错框架,故障定位快速准确,层次化恢复,兼容主流大模型训练框架
多层次异步检查点读写,通过共享内存和本地磁盘缓存降低故障恢复和加载开销,故障时即时保存检查点,优化通信操作的故障识别与恢复
低开销自动并行策略搜索,资源动态变化时自动调整训练并行度
Resilio系统
容错框架
故障感知:拦截函数调用,统计CUDA核心指标到共享内存,持续监控并判定Error、Slowdown
生命周期管理:处理提交的作业、调度资源、检验环境可用性、创建分布式进程、故障后启动层次化恢复
检查点控制器:显式保存检查点,初始化(组建通信域等)时从持久化存储中预加载检查点
指标上报:规范上报硬件、训练状态数据,提高故障判断准确性
检查点高效存储
多层次异步访存优化
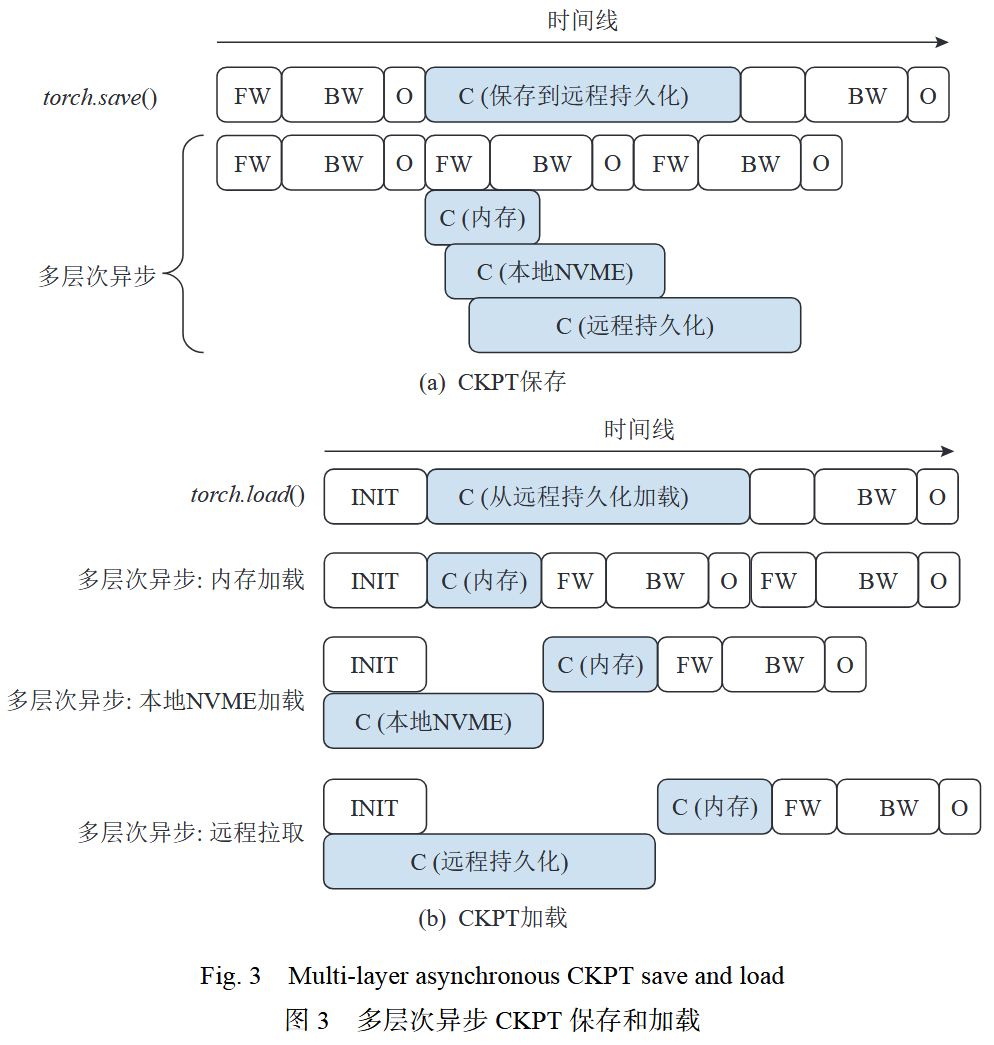
部分元信息序列化
锁页内存及CUDA多流,充分利用显存到CPU内存间带宽
异步切片传输持久化
模型初始化的同时将本地或远程检查点副本拷贝到内存中,故障恢复时按故障划分:
无需重启:内存读取
需要节点替换:新节点远程拉取,其他进程本地磁盘读取
即时检查点
大模型训练特征
3D并行中的数据并行维度模型副本一致,模型参数更新前需要全局同步
单点故障
进程故障导致集合通信超时
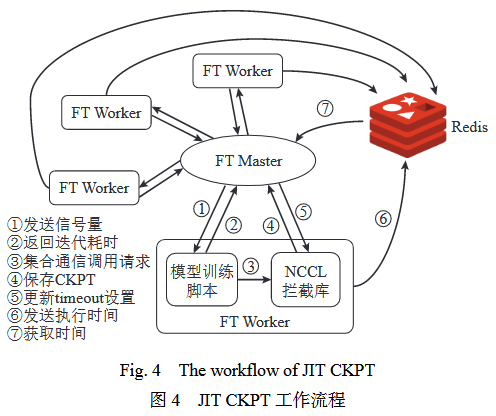
FT Master收集超时事件,判定收到的为健康进程、未收到为故障进程,在故障进程的数据并行组内寻找健康进程来保存检查点,若无则结束所有FT Worker
自适应并行策略调整
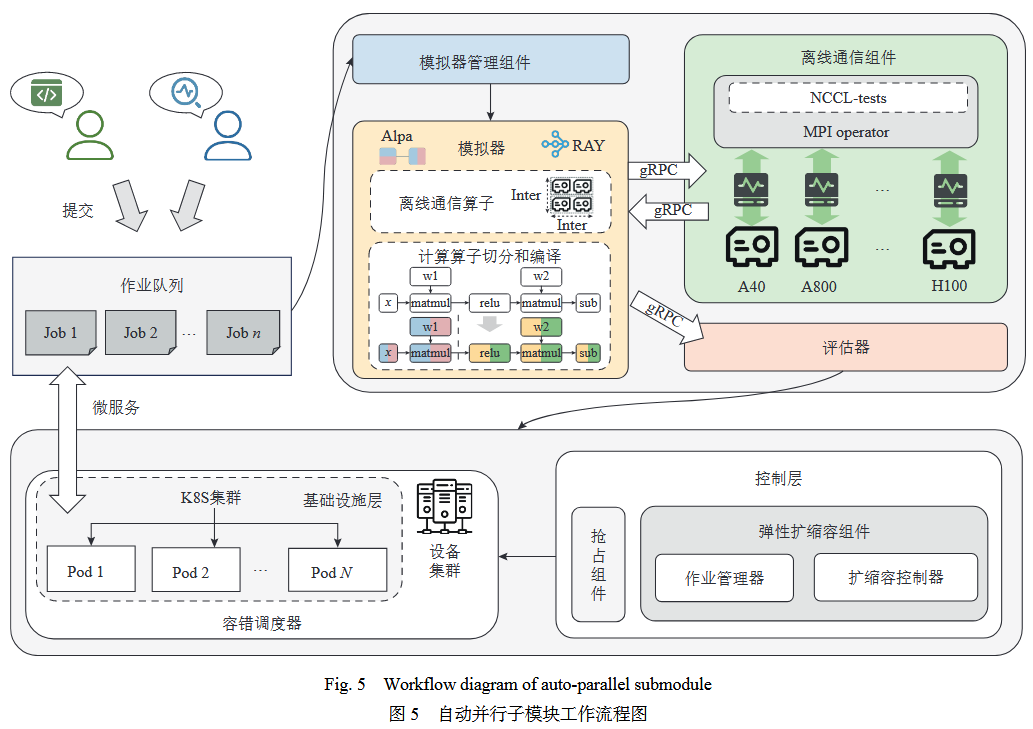
模拟器实例接收由模拟器管理组件传入的 GPU 资源类型、资源个数和流水线并行度,自动搜寻当前配置下的最优自动并行策略并评估模型的端到端时延
模型计算图编译和流水线阶段聚合
流水线切分算法
计算资源评估和并行策略搜索
3D并行各维并行度搜索算法
端到端时延计算
根据上述步骤按迭代时间选择最优配置调度,当集群空闲资源不足时选择次优
当任务选择分布式数据并行配置时,自动弹性扩缩容

实验与结果
结合Megatron-LM测试12节点8卡A100集群训练GPT-109B的故障端到端恢复耗时
对比DLRover 4.0测试故障端到端恢复耗时、检查点保存加载耗时
测试系统性能开销
对比Alpa测试模拟器并行度搜索耗时、精度与MFU
评论区