



NSDI 23
容器操作系统级GPU共享,性能隔离
PJ+OJ,只考虑训练
引入
背景
容器广泛应用,方便部署和管理
DL被应用和在线服务广泛使用,企业建立大规模多租户GPU集群训练DL模型
问题
容器独占GPU的模式能保证性能隔离但是利用率低下,排队时间长
解决
GPU共享能提高利用率,生产中,任务分PJ(生产任务,要保证性能)和OJ(机会任务,用空闲资源)两类
GPU共享
可在应用层和OS层实现
现有方案缺陷
应用层的AntMan修改DL框架为侵入式
OS层的MPS会捆绑作业进程到单一CUDA上下文,无法隔离错误
挑战
应用无关的GPU资源分配
显存超额请求处理
贡献
容器云上的透明GPU共享机制
自适应速率控制与透明统一内存机制,实现高GPU利用率和性能隔离
与Docker和Kubernetes集成,实验证明
吞吐量影响小
吞吐量与SOTA AntMan相当,优于MPS15倍
背景
容器云
略
DL训练负载
略
现有共享方案局限
应用层
非透明,DL框架修改,版本更新与维护,用户学习成本
OS层
MPS
需要预设应用的资源限制,总进程显存需适配GPU显存,需要自行处理显存与内存交换
无法隔离故障,CUDA上下文合并导致进程单点故障
MIG
需要高端GPU硬件支持
GPU只能按预设7种配置分割,最多能占4/7计算资源,1/2显存
不能动态调整分配到容器的GPU资源
重新配置MIG需等GPU空闲
TGS概述
目标
透明
负载无关
高GPU利用率
计算和显存利用率都要高
性能隔离
PJ尽量不受OJ影响
故障隔离
容器间故障不互相影响
架构
OS级,位于容器与GPU之间,容器与应用无感知
通过内核拦截与调控在多个容器间共享GPU资源
核心
自适应共享GPU计算资源而无需应用知识
监控容器性能指标,根据CUDA块数调节内核提交速率,平衡PJ性能和OJ吞吐量
透明的显存超额请求处理
不修改DL框架且自动进行显存-内存交换
使用CUDA统一内存技术整合显存与内存到同一地址空间,映射超额部分显存到内存
优先为PJ分配显存
轻量化低开销;GPU上下文独立,故障隔离
TGS设计
解决准确估算PJ剩余资源问题
解决严格控制OJ资源使用量问题
共享GPU计算资源
假想方案:优先级排序(标准方案)
步骤
设置生产队列PQ、机会队列OQ
拦截所有容器GPU内核任务,PJ内核到PQ,OJ内核到OQ
仅当PQ为空时再调度OQ中的内核到GPU
可实现性能隔离和高GPU利用率
缺陷
PQ为空不代表PJ未占用GPU,历史内核可能还在执行
PQ为空无法反映GPU剩余资源量,调度OJ内核可能导致资源竞争严重影响PJ
无法跟踪运行的内核,不同型号GPU特性不同
TGS方案:自适应速率控制
核心思路
根据内核到达速率精细调整内核出队速率,使OJ充分利用剩余资源并尽量降低对PJ的影响,同时该方法与GPU解耦
实现
考虑速率控制需要观察的信号,由于训练过程指标无法感知,考虑使用GPU利用率
驱动报告的利用率无精确定义
GPU利用率与应用程序性能仅存在弱相关性,利用率低于100%不意味着可以提高OJ出队速率,因为某些单元可能已经满载
使用PJ队列内核到达速率作为信号,只调节OJ内核出队速率
内核到达率直接反映训练速度和吞吐量
可以反映GPU缓存、CPU、网络等所有资源竞争;可以调控资源请求超额时的竞争
通过滑动平均估算,过滤微小波动
算法
经验构建
α 表示PJ队列,β 表示OJ队列
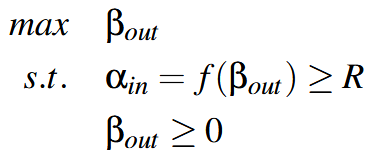
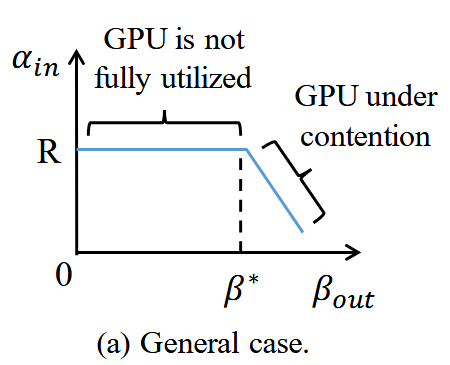
通过AIMD(加增乘减)调控 βout,使其逼近 β*(αin下降临界点)
R 波动时,停止OJ内核出队并重新测量R
共享GPU显存
假想方案:直接分配
直接将容器的显存调用传给GPU
缺陷
当OJ占据剩余显存时,如果PJ显存需求增加,OJ无法让出显存,造成PJ降速或失败
某些框架(TF)启动时会抢占所有可用显存,且不主动释放,可通过修改DL框架解决,但非透明
TGS方案:统一显存和内存
通过CUDA统一内存技术,显存可以和内存整合到同一地址
拦截所有容器的内存调用,并在统一内存空间中分配内存
当显存占满时,保留PJ任务数据块,必要时迁移OJ任务数据块到内存
实际需要的数据在内存时,通过GPU缺页拦截处理移至显存,不需要的仍在主机内存中,高效共享显存
实现
与Docker和Kubernetes集成
自适应速率控制
拦截容器的内核相关的CUDA驱动API调用,监控速率,使用全局计数器统计CUDA块数量
将PJ容器速率发送给同GPU上OJ流量控制组件,当OJ容器超出预设速率阈值时,延迟内核启动指令的执行
统一内存管理
拦截所有GPU内存分配相关CUDA驱动API调用,替换为CUDA统一内存分配调用
自定义新调用API,优先为PJ容器分配显存;PJ容器终止时预取OJ容器在内存中的数据
实验
负载
自定义多领域经典模型训练
baseline
直接共享执行
MIG
MPS
独立执行
指标
吞吐量
JCT
Trace(运行时间)
Philly
实验加速
Fast-forwarding
来自Gandiva,在没有调度事件时跳过多轮mini-batch迭代
实验
一个PJ与一个OJ同时到达且共置,在显存充足时,测试低、高资源竞争时不同方法的吞吐量和JCT
同上,但显存需求超额
模拟任务流场景下,测试不同方法avgJCT和相应CDF
测试不同模型共置时有无TGS的吞吐量
时域上,在PJ中途与OJ共置场景下,记录SM利用率和吞吐量变化
时域上,PJ与OJ同时到达且共置,但PJ的GPU利用率随时间变化,记录SM利用率和吞吐量变化
不同框架,测试吞吐量
与应用层的antman对比,测试吞吐量
双卡训练GPT作为PJ与两个单卡OJ共置,测试吞吐量
讨论
分布式训练不是GPU共享的主要场景,GPU闲置可能性低
可与GPU集群调度方法正交互补
GPU空间共享需要硬件支持且不成熟,所以采用时间共享
评论区